Introduction
Miombo woodland ecosystems play a vital role in the global carbon cycle. However, it is currently difficult to know how much carbon they store and sequester due to a lack of data. Therefore, an accurate estimation of forest aboveground biomass (AGB) is required to provide the baseline of forest carbon stocks and quantify the anthropogenic emissions caused by deforestation and forest degradation. In addition, accurate estimation of forest AGB is critical to implementing cost-effective carbon emission mitigation strategies.
Challenges and opportunities
Forest AGB stocks are traditionally assessed using field-based plot inventory and destructive biomass sampling approaches. Forest researchers select some plots and collect tree structural parameters such as diameter at breast height (DBH) and tree height. Then scientists develop allometric equations to estimate forest AGB based on the tree structural parameters. This conventional approach is valuable to a certain extent. However, it is expensive and time-consuming over a vast forest area, limiting scalability. Furthermore, field-based inventory and destructive biomass sampling approaches can introduce sampling bias at a local scale.
Earth observation (EO) technology allows for large-scale assessments of the forest ecosystem, structure, and functionality. Forest researchers and scientists can cost-effectively employ field-based plot inventory and remotely-sensed data. In general, optical, radar and lidar sensors mounted on ground-based, airborne and spaceborne platforms collect remotely-sensed data. Researchers and scientists use plot inventory, remotely-sensed data, and parametric or non-parametric machine learning (ML) approaches to model forest AGB.
Parametric approaches comprise statistical regression models and semi-empirical models. In general, parametric methods assume that the relationship between the dependent and independent predictor variables has explicit model structures, interpretable a priori through parameters. For example, multiple linear regression models have been commonly used to predict forest AGB. However, the relationship between forest AGB and remote sensing variables is often too complex and non-linear. Therefore, researchers and scientists have adopted data-driven non-parametric ML approaches to model complex non-linear relationships between forest AGB and predictor variables.
Dealing with uncertainty
One of the significant challenges is how to deal with forest biomass estimation uncertainty from both field-based plot inventory and remote sensing methods. Researchers and scientists need to identify the uncertainty sources in the land-use and biomass estimations for different land cover classes and emission factors. Then the overall uncertainty of the biomass estimation can be quantified and reported. There are many recommended methods to analyze forest biomass estimation uncertainty. This blog post series will perform uncertainty analysis based on cross-validation (CV) and explainable machine learning approaches.
Purpose of the Blog Post
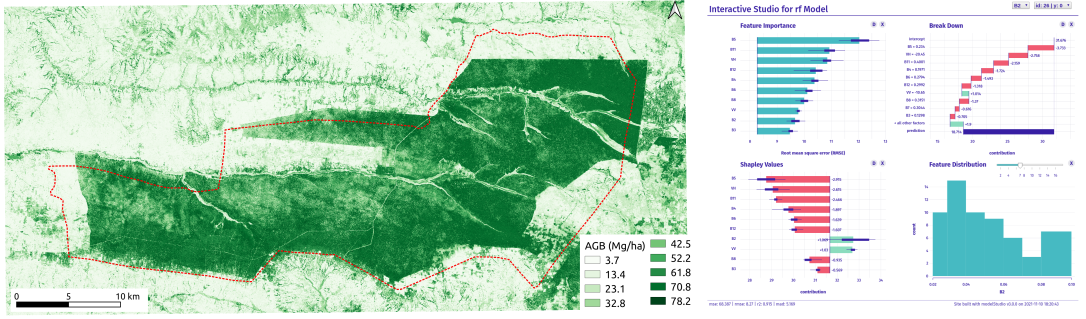
This blog tutorial will model forest AGB using Sentinel-1 and Sentinel-2 data and a random forest regression model.
Procedure
First, we will train a random forest (RF) model using forest AGB training data and Sentinel-1 and Sentinel-2 data. In this post, we will use Mafungautsi Forest Reserve in Zimbabwe as a test site. Readers can access the blog tutorial, sentinel-1 and sentinel-2, and training data in the link below.
Readers can also click the link below to access the interactive dashboard and explore the RF predictive model.
Next Steps
I have prepared an introductory guide to perform explainable machine learning.

If you want to learn more about explainable machine learning, please download the guide for free at: